浏览器原理浅析(补充)
引用
DOM树如何形成
假设有一个html文档,代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div>
<h1 class="title">demo</h1>
<input value="hello">
</div>
</body>
</html>
tokenize过程会将HTML结构通过分词器将字符流拆分为词(token),例如下面的格式:
[{"tagName":"html","type":"DOCTYPE","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"html","type":"StartTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"head","type":"StartTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"meta","type":"StartTag","attr":"charset=utf-8","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"head","type":"EndTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"body","type":"StartTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n "},{"tagName":"div","type":"StartTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n "},{"tagName":"h1","type":"StartTag","attr":"class=title","text":""},{"tagName":"","type":"Character","attr":"","text":"demo"},{"tagName":"h1","type":"EndTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n "},{"tagName":"input","type":"StartTag","attr":"value=hello","text":""},{"tagName":"","type":"Character","attr":"","text":"\n "},{"tagName":"div","type":"EndTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":" \n"},{"tagName":"body","type":"EndTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"html","type":"EndTag","attr":"","text":""},{"tagName":"","type":"Character","attr":"","text":"\n"},{"tagName":"","type":"EndOfFile","attr":"","text":""}]tagName指我们在HTML文件内编写的元素标签。attr是我们为元素添加的属性。text则表示元素内部的文本内容。
至于type,Chrome内部总共定义了七种标签类型:
enum TokenType {
Uninitialized,
DOCTYPE,
StartTag,
EndTag,
Comment,
Character,
EndOfFile,
};
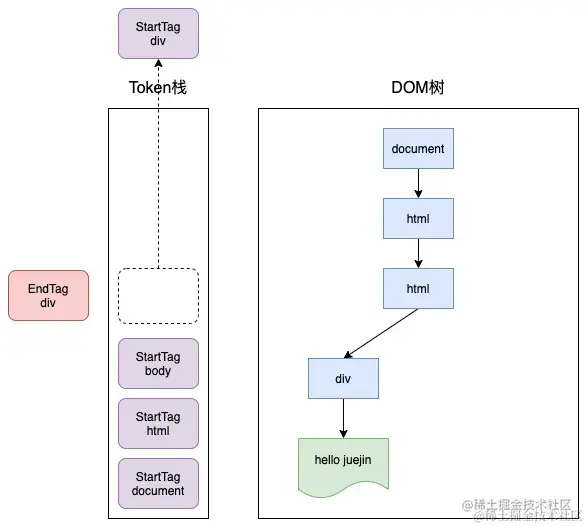
接下来就需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。这个过程是通过栈结构来实现的。在对上一步的解析后得到的数据进行遍历时,根据不同的type进行不同的处理。
switch (token->GetType()) {
case HTMLToken::kUninitialized:
case HTMLToken::kCharacter:
NOTREACHED();
break;
case HTMLToken::DOCTYPE:
ProcessDoctypeToken(token);
break;
case HTMLToken::kStartTag:
ProcessStartTag(token);
break;
case HTMLToken::kEndTag:
ProcessEndTag(token);
break;
case HTMLToken::kComment:
ProcessComment(token);
break;
case HTMLToken::kEndOfFile:
ProcessEndOfFile(token);
break;
}如图所示: